Manage (change, use, re-organize, …) data in a DataSource.
With an Actionable of type “Before With DataSources” you can use the simplicity and power of PDF Butler DataSources and still manage the data before calling PDF Butler.
Some examples of where this is useful:
- Making calculations
- Retrieving images from Rich Text fields
- Re-ordering data
- Using the data selected to do a callout
- Removing data according to complex logic
This manipulation of data can be done directly in APEX.
global with sharing class PB_Act_YourCoolDataLogic implements cadmus_core.AbstractBeforeWithDataSourcesActionable{
global void execute(cadmus_core__Actionable__c actionable, Id docConfig, Id objectId, Map<String, Object> inputMap, Map<String, Object> dsMap, cadmus_core.ConvertController.ConvertDataModel cdm) {
System.debug('Starting!');
System.debug(dsMap);
// DO YOU CUSTOM LOGIC ON THE DATA HERE
}
}
- This class and the “execute” method have to be “global”.
- The class must implement interface “cadmus_core.AbstractBeforeWithDataSourcesActionable”
Retrieve a DataSource from the Map (variable dsMap) #
In the input variables of the “execute” method, there is a Map with all DataSources. The key of the map is the “Customer DataSource Id”. This Id can be found on your DataSource in field “cadmus_core__CustomerDataSourceId__c”. As this field is unique over all environments (eg Sandboxes and PROD). As this “Customer DataSource Id” is unique and remains the same over all environments, it can be used in your code and can be deployed with your code to other environments.
It is important to remember that PDF Butler will use Maps and Lists. Not the Salesforce SObject.
- A record is a Map<String, Object>
- Multiple records are grouped into a List of records: List< Map<String, Object>>
To retrieve a DataSource from a Map use this code:
For a SINGLE DataSource:
Object rowDs = dsMap.get('00DAU00000D8etd_a5WAU000000CCLZ');
Map<String,Object> row = ((cadmus_core.SingleWrapper)rowDs).data;
System.debug(row);
For a LIST DataSource:
Object rowsDs = dsMap.get('00DAU00000D8etd_a5WAU000000CCLZ');
List<Map<String,Object>> rows = ((cadmus_core.ListWrapper)rowsDs).data;
System.debug(rows);
for (Map<String,Object> row : rows) {
//We are looping over the records
}
Use coding best practices to check for null values. They might be reasons the DataSource is not in the Map.
It is also possible to customize the Actionable with custom fields, Record Type and Page Layout. All fields on the Actionable__c SObject will be available in your code.
This means you can add custom fields, lookups, … that are easily accessible in your APEX Actionable.
Example: String myFieldValue = actionable.My_Custom_Field__c
Retrieve fields from a record #
To retrieve fields, just get them by the field API name from the Map (remember that a Map is a record).
//MAKE SURE THAT ALL FIELDS REQUIRED ARE IN THE DATASOURCE!
//Get a String value:
String val1 = String.valueOf(row.get('String_Field__c'))
//Get a Numeric value:
Double val1 = (Double)row.get('Amount')
//Get a String value from a Lookup field:
String val1 = String.valueOf(row.get('MyLookup__r.My_String_Field__c'))
Add fields to a record #
To add fields, just add fields to the Map (remember that a Map is a record).
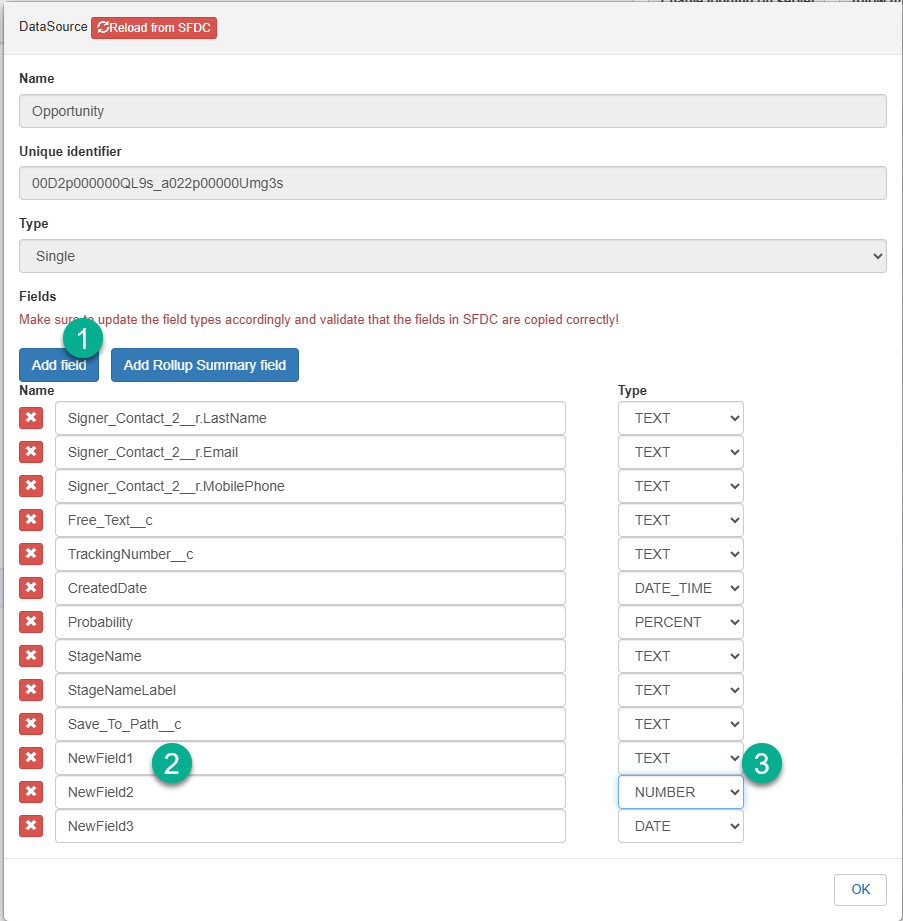
row.put(‘NewField1’, ‘Hello World’); row.put(‘NewField2’, 12.2); Date myDate = Date.today(); row.put(‘NewField3’, myDate);
Update fields in a record #
row.put(‘String_Field__c’, ‘Hello World’); row.put(‘Amount’, 12.2);
Update PDF Butler configuration with the new fields #
If you want to use these fields in PDF Butler configuration. You will have to add these manually into the DataSource.
- Open the DataSource and click “Add field” button for each field you want to add
- Fill the field name
- Set the data type of the field
Update the data in the DataSource Map: #
Fields added or updated in the record Maps are automatically ready and available for PDF Butler to be processed in the DocConfig. No extra steps required.
Add data to a new DataSource: #
If you want to add a new DataSource or want to use a new record Map for an existing DataSource. It is required to add your data to the map via code:
When the data has to go to a new DataSource. This is most likely a KeyValue DataSource. You can add a KeyValue DataSource and retrieve the “Customer DataSource Id”. To learn more about KeyValue DataSources: https://www.pdfbutler.com/academy/pdf-butler-academy/pdf-butler-by-datasource/keyvalue/
Also make sure the DataSource is added to the DocConfig via the DocConfig configuration screen.
//Add a SINGLE DataSource
Map<String,Object> keyValueDs1 = new Map<String, Object>();
//DO YOUR CUSTOM LOGIC TO ADD FIELDS TO THE RECORD
cadmus_core.SingleWrapper dsSingle1 = new cadmus_core.SingleWrapper();
dsSingle1.data = keyValueDs1;
dsMap.put('00DAU00000D8etd_a5WAU000000CCLZ',dsSingle1);
//Add a LIST DataSource
List<Map<String,Object>> keyValueDs2 = new List<Map<String, Object>>();
Map<String,Object> myRecord = new Map<String, Object >();
keyValueDs2.add(myRecord);
//DO YOUR CUSTOM LOGIC TO ADD FIELDS TO THE RECORD
cadmus_core.ListWrapper dsList1 = new cadmus_core.ListWrapper();
dsList1.data = keyValueDs2;
dsMap.put('00DAU00000D8etd_a5WAU000000CCLY',dsList1);
Set the Actionable to run your class: #
As this is an Actionable that runs before PDF Butler is called it has to be added to the DocConfig.
If you are running a Pack, the Actionable must also be linked to this Pack!
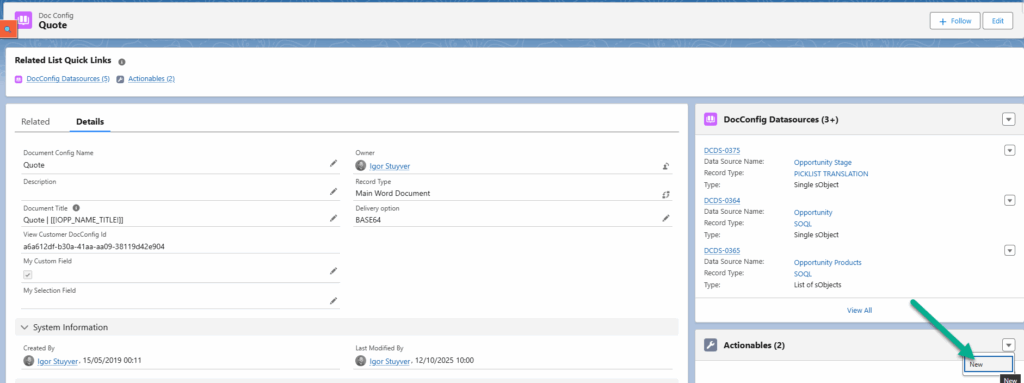
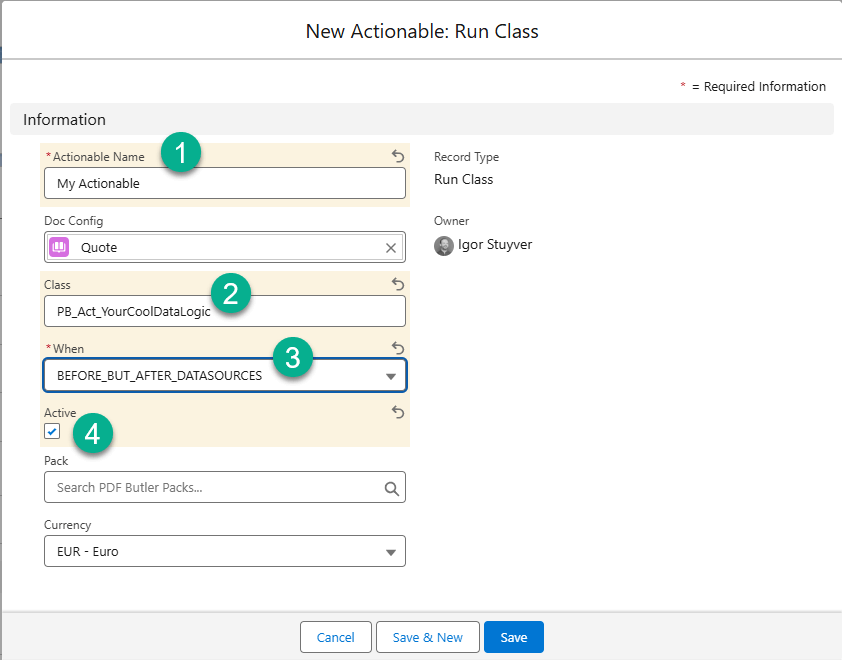
- On the DocConfig create a new Actionable:

- Select the Record Type “Run Class”
- Fill the information
- A custom name
- If you have multiple Actionables of the same “When”, they will run in alphabetical order
- The name of the class you created
- When to run this Actionable: Before document generation but after the DataSources have been populated
- Activate the Actionable

- A custom name